
-
Red-Black Tree in Linux Kernel - Part 2
작성: 숲사람
지난 포스트에서 Red Black Tree의 일반적인 동작 방식을 이해
하려고 시도해 보았다. 이번 포스트에서는 Linux Kernel에서 RB Tree가 어떻게 구현되었는지 살펴볼 것이다. 최신 리눅스 커널 버전은 v5.15 이지만, 이 문서를 쓰던 당시 커널버전은 v4.6 이었기 때문에 소스코드 분석은 v4.6버전 기준으로 하였다. 참고한 소스코드는 문서 하단 References 참고.Kernel source에는 lib/rbtree_test.c 파일이 있다. Kernel에서 RB tree를 어떻게 사용하는지 친절하게 예를 들어주는 파일이다. 이를 통해 RB tree 사용법, 그리고 lib/rbtree.c 파일을 분석함으로써, Kernel에서 RB tree의 Insert / Erase 동작은 어떻게 구현되었는지 파악 해볼 것이다.
아래 소스코드를 보면
|+""등이 함께 표현되어있는데, 이는 중요도가 낮은 코드는 제거, 불필요한 공백과 indent 를 처리하고, 다른 파일에 위치한 코드를 쉽게 따라가기 위해 내가 만든 코드 분석 방법이다(추후 설명페이지 공유예정).
사용법 및 구조체 분석
Linux Kernel RB Tree API 사용법 요약
자세한 내용은 lib/rbtree_test.c 파일 참고
- 구조체에 struct rb_node * 멤버 추가
- 전역 rb_root 구조체 변수 생성
- my_insert 함수 작성
- my_erase 함수 작성
rb_node구조체struct rb_node { unsigned long __rb_parent_color; /* rb parent and color */ struct rb_node *rb_right; struct rb_node *rb_left; } __attribute__((aligned(sizeof(long))));-
실제 rb tree규칙으로 트리의 균형이 맞는지 rebalence 되는 노드의 구조체.
__attribute__((aligned(sizeof(long))));의미는?
구조체의 시작 주소 정렬
구조체의 시작주소가 4또는8의 배수(long크기)가 됨.
long형은 32bit 일때는 4byte, 64bit 일때는 8byte
참고: http://gcc.gnu.org/onlinedocs/gcc-4.6.1/gcc/Type-Attributes.html#Type-Attributes-
__rb_parent_color에는 부모노드의 주소값이 long으로 형변환되어 저장된다.
주소는 4 혹은 8의 배수로 증가하기 때문에 하위 2~3비트는 사용되지 않는다.
rb_node에서는 이 사용하지 않는 비트를 색 지정으로 사용하여 추가 변수 필요없이 메모리 공간을 절약한다.
그래서 rb_parent_color 멤버 변수를 통해 부모노드 주소__와 __본인노드 색 두가지를 동시에 가질 수 있다. __rb_parent_color변수의 더 정확한 의미는 rb parent and color이다.
-
Red-Black Tree in Linux Kernel - Part 1
작성: 숲사람
Red-Black Tree 란?
RB-Tree 는 Radix-Tree와 더불어 Linux Kernel에서 가장 많이 사용하는 Tree 자료구조이다. I/O scheduler(CFQ, deadline 등), ext filesystem, Virtual memory areas 등 Kernel의 여러 Subsystem에서 사용된다. 기존 Tree자료구조의 단점은 최악의 경우 노드가 Linked-List의 형태로 저장되어 탐색 시간복잡도가 O(N) 이 된다는 점이다. 하지만 RB Tree는 노드의 삽입과 삭제가 이루어 질때, Tree가 자동으로 회전하며 O(logN)의 시간복잡도를 보장한다.
이 글에서는 일반적인 RB Tree에서 가장 복잡한 연산인 삽입과 삭제가 어떤 방식으로 동작 하는지 알아본다. 경우의 수만 잘 따지고 그때그때 어떻게 해주는지 규칙만 잘 파악하면 쉽게 따라갈 수 있다. 이를 기반으로 해서 다음 글에서 Linux Kernel 에서 RB Tree가 어떻게 구현되었는지 살펴 볼것이다.
RB tree의 5가지 규칙
노드의 삽입과 삭제연산을 할때마다, 아래의 규칙을 만족시키도록 트리의 노드위치를 변경하거나 유지하는것이 RB Tree이다.
- 노드는 빨간색 검은색 둘 중 하나다(A node is either red or black)
- Root 노드는 검은색이다. (The root is black)
- 모든 말단 노드는 검은색이다 (All leaves (NULL) are black)
- 빨간색 노드는 중첩될 수 없다. (Both children of every red node are black)
- 각 말단노드의 Black Height는 모두 동일하다 (Every simple path from root to leaves contains the same number of black nodes)
Black Height: 말단노드에서부터 Root노드 사이의 검은색 노드 갯수
삽입 연산
새노드가 트리에 삽입될때, 부모노드는 검은색인경우 빨간색인 경우 두가지가 있다. 아래 설명된 각각의 경우의 수에따라 5가지 종류의 삽입연산이 필요하다.
새노드 삽입 insert_case1() 수행 -검은색에 삽입 -> 문제가 되지 않음 -빨간색에 삽입 (1) 삼촌도 빨간색인 경우 insert_case3(n) 부모,삼촌 검은 색, 할아버지 빨간색으로 (2) 삼촌이 검은색인 경우 (여기서 삼촌은 할아버지의 오른쪽 자식으로 가정) 1) 삽입노드가 부모노드의 오른쪽 자식인 경우 insert_case4(n) 삽입노드와 부모노드를 회전시켜 부모노드를 삽입노드의 왼쪽 자식으로 만든다. --> 2)과 구조가 됨 2) 삽입노드가 부모노드의 왼쪽 자식인 경우 insert_case5(n) 부모노드를 검은색 할아버지 노드를 빨간색으로 바꾸고 오른쪽회전 (부모노드가 루트위치로)일부 삽입연산은 트리의 회전연산이 필요하다(rotation_left() 및 rotation_right()). 회전연산은 매개변수로 전달된 노드의 자식을 치켜세워주는 연산이라고 생각하면 이해하기 쉽다 : 자식이 위로 부모는 아래로. 아래 그림은 부모노드(O)와 자식노드(N) 기준으로 rotation_left 회전이 일어날때 트리의 구조 변화이다.
P P / / (O) (N) / \ / \ l (N) --> (O) r / \ / \ m r l m각각의 삽입 연산 동작 방식은 아래와 같다.
insert_case1(n) { if (부모노드가 없는경우) -> n을 블랙 (루트노드가됨) else (부모노드 있으면) insert_case2(n) 수행 }insert_case2(n) { if ( 부모노드가 블랙인경우 ) 그냥 삽입해도 문제 안되므로 return else(부모노드 빨강) insert_case3(n) 수행 }insert_case3(n) { if( 삼촌노드 빨간색이면 && 삼촌노드 있으면) 부모,삼촌노드 검은색으로 할아버지노드 빨간색으로 insert_case1( 할아버지노드) " 재귀적으로 수행 !!" else "그외 나머지 경우 (삼촌 노드가 검정색 || 삼촌노드 없으면)" insert_case4 (n) }insert_case4()는 case5 함수를 수행할 구조로 만드는 작업이다.
insert_case4(n) { if (부모노드가 할아버지 노드의 왼쪽자식 && 새노드가 부모노드의 오른쪽자식 ) rotation_left(부모노드) n = n->왼쪽노드 if(부모가 할아버지의 오른쪽 자식 && 새노드가 부모 노드의 왼쪽 자식) rotation_right(부모노드); n = n->오른쪽노드 둘다 아니거나 위내용을 수행했으면 insert_case5(n) 수행 }insert_case5(n) { 부모는 검은색으로 할아버지는 빨간색으로 if ( 부모가 할아버지의 왼쪽자식 && n이 부모의 왼쪽자식 ) rotation_right( 할아버지 노드) else (부모가 할아버지 오른쪽 자식 && n이 부모의 오른쪽 자식 ) rotation_left( 할아버지 노드) }삭제 연산
삭제 연산은 삽입 연산보다는 다소 복잡한데, 삭제되는 노드를 처리해야하고, 삭제된 자리를 새로운 후계자 노드로 변경해야하기 때문이다.
삭제되는 노드 처리
삭제되는 노드에 대체되는 노드를 복사한다. 색은 삭제되는 노드색을 유지하고, 노드만 바로 복사된다. 대체될 수 있는 후계자는 이진트리 삭제와 마찬가지로 left 하위트리 에서 가장 큰 노드인데(삭제 노드의 왼쪽sub트리는 Inorder Predecessor 오른쪽은 Inorder successor라고 표현함), 보통 맨 아래 노드이고 (leaf node가 1개와 Null leaf1개) 이거나 (Null leaf만 두개)인 경우밖에 없다. 중요한건 이 대체되는 후계 노드가 그 자리에서 삭제 된다는것인데, 이때 RB트리의 규칙이 무너지는 경우가 있기 때문에, 대체되는 노드를 기준으로 아래 2번의 알고리즘을 따르게 된다. 가령 아래 트리에서 노드 40이 삭제된다면 그자리를 대체할 수 있는 후계노드는 노드 30이 될것이다.
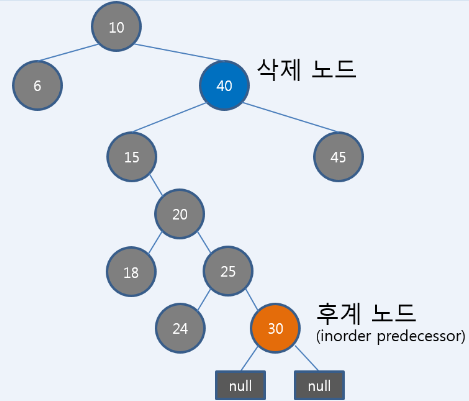
아래 설명에서 n은 대체될 노드의 자식이다. 일반 노드가 될 수 도 있고 Null leaf(검은색)가 될수도 있다. 즉, 트리에서 삭제되는 노드 기준으로 트리 balancing동작을 시키는 것이 아니라 후계자 노드 기준으로 balancing동작 수행한다.
후계자 노드 처리
후계 노드가 삭제되는 것으로 판단하면 된다. 후계 노드가 빨간색일 경우와 검은색일 경우에 따른 케이스로 구분하면 된다. 아래 형제,부모,조카는 대체될 후계 노드 기준으로 위치한 노드이다. 실제로는 대체될 후계노드의 자식노드기준으로 볼 수도 있는데. 그이유는 대체될 노드는 삭제노드 위치로 변경되고 대체될 노드의 자리에는 어차피 그 노드의 자식노드가 위치할 것이기 때문이다.
- 후계노드가 빨간색 -> 문제 없음 - 후계노드가 검은색 - 형제가 빨간색인 경우 delete_case2(n) - 형제가 검은색인 경우 (3) 부모노드 검은색, 형제의 양쪽 자식이 모두 검은색 : delete_case3(n) ->형제노드만 빨간색으로 (4) 부모노드는 빨간색, 형제의 양쪽 자식이 모두 검은색 : delete_case4(n) ->형제:빨간색 부모:검정색 (5) 삭제노드와 가까운 조카노드가 빨간색일때 : delete_case5(n) -> 형제와 조카노드 색교환, 형제기준 조카노드를 올리는 방향의 회전 (아래 case6 조건으로 변경됨) (6) 삭제노드와 먼 조카노드가 빨간색 (가까운조카색 관계없음) : delete_case6(n) 형제는 부모노드 색으로, 부모는 검은색으로 멀리있는 조카노드 검은색으로 부모노드 기준 형제를 올리는 방향의 회전삭제되는 후계자 노드 위치 기준으로 delete_one_child() 부터 시작한다.
"여기서 n은 실제 트리에서 제거될 후계 노드의 자리를 차지하게 될 노드임에 주의" delete_one_child(n) { child = is_leaf() "n의 자식" child(n의 자식)를 삭제될 n(후계노드)있던 자리로 변경 if( n == 블랙) if ( child == 레드) child 블랙으로 변경 else delete_case1(child) 호출 "n의 자식으로 case 1 부터 start!" "여기서 child의 위치는 후계노드의 원래 위치와 동일함" }"여기서 n은 대체노드의 자식노드 child임에 주의" delete_case1(n) { if (삭제노드의 부모가 NULL이 아니면) delete_case2(n) 호출 }"형제를 검은색, 부모를 빨간색으로 바꾸고 left/right회전!" delete_case2(n) { if (형제 == 레드) 부모노드를 빨간색, 형제노드를 검은색 변경 if ( n == 부모의 왼쪽자식) rotation_left(부모노드) else rotation_right(부모노드) delete_case3(n) 호출 }delete_case3(n) { if (형제==블랙 && 부모==블랙 && 형제 좌/우 자식==블랙) 형제를 빨간색 deletion_case1(부모노드) 호출 else deletion_case4(n) 호출 }delete_case4(n) { if (형제==블랙 && 부모==레드 && 형제 좌/우 자식==블랙) 형제를 빨간색 부모를 검정색으로 else deletion_case5(n) 호출 }delete_case5(n) //case6 를 수행할 구조로 만드는 작업 { if (형제 == 블랙) if (n이 부모노드의 왼쪽자식 && 형제 오른쪽자식==검정 && 형제 왼쪽자식==빨강) 형제노드 빨간색으로 형제 왼쪽 자식 검은색으로 rotation_right(형제노드) else if (n이 부모노드의 오른쪽 자식 && 형제 왼쪽자식==검정 && 형제 오른쪽자식==빨강) 형제노드 빨간색으로 형제 오른쪽 자식 검은색으로 rotation_left(형제노드) deletion_case6(n) 호출 }delete_case6(n) { 형제색 = 부모의 색으로 부모색 = 검정색으로 if (n이 부모의 왼쪽 자식이면) 형제의 오른쪽자식 검정색 으로 rotation_left(부모노드) else "n이 부모의 오른쪽 자식" 형제의 왼쪽자식 검정색 으로 rotation_right(부모노드) }References
-
If 없이 Shell Script 분기 처리하기
if [ condition ]; then cmd fi나는 쉘스크립트를 처음 배울때, 일반적으로 사용되는 이 If 구문이 다소 난해하게 느껴졌다.
then의 존재가 생소했고,[]의 대괄호가 정확히 무엇을 의미하는지 그리고 세미콜론이 왜 붙는지 등. 이해하지 않고 그냥 외웠다. 그래서 한때는;를then뒤에 붙여야하는지 앞에 붙여아하는지 햇갈려서 매번 구글 검색을 했다. 이것들의 정확한 의미는 무엇일까?한편 쉘스크립트를 작성할때, If Statement를 사용하지 않고도 분기 처리하는게 가능하다. 꽤 많은 경우에
ifelse대신&&||를 사용한다면 훨씬 깔끔하고 명료한 분기문을 작성 할 수 있다. 이 글에서는ifelse대신&&||를 사용하는 분기에 대해 알아보고, 쉘스크립트의 IF Statement의 구조에 대해 조금더 명확하게 이해해 볼 것이다.
-
GNU autotools 로 UNIX스럽게 프로젝트 구성하기
빌드 시스템
프로젝트의 소스코드가 한두개가 아니라 수십 수만개가 되면 gcc 로 일일이 컴파일을하여 하나의 executable 실행파일로 생성하는것은 불가능하다. 이를 위해 make 빌드시스템이 고대에 도입되었다(It was originally created by Stuart Feldman in April 1976 at Bell Labs.). make는 Makefile이라는 파일을 이용해 소스코드를 컴파일하고 빌드한다. Makefile은 컴파일을 위한 쉘스크립트라고 보면 쉽다. 일반 쉘스크립트를 이용해 빌드환경을 만들수 도 있다. 그러나 보통 쉘스크립트는 빌드환경에 특화되어있지 않기 때문에 거의 사용하지 않는다. 참고로 쉘스크립트와 Makefile 스크립트의 다른점 중 하나는 Increamental Build인데, 기존에 빌드를 진행한적이 있다면, 그 뒤에는 make가 최근 수정된 소스코드만 컴파일하여 최종 executable에 링크하는 를 할 수 있다.
또한 소스코드의 파일이 방대한경우 그리고 빌드하는 환경이 유저마다 서로 다른경우, 또한 여러가지 기능들을 사용자가 추가/제거 하고 싶은경우 Makefile에서 모든것을 처리하는게 쉬운일은 아니다. 그래서 대부분의 UNIX 유틸리티의 소스코드 패키지에는 autotools 로 생성한 configure파일 그리고 Mafefile.am파일이 존재해서 사용자가 직접 본인의 UNIX 환경에서 Makefile을 생성하게끔 한다. GNU autotools는 이렇게 불편을 최소화하기 위해 소스코드 패키지를 여러 UNIX계열 시스템에 이식성(portable)가능하게 만들어주는 도구다. 다시말해 이식성 가능한 프로젝트 빌드를 가능하게 해주는 도구다.
make는 거의 무려 50년전에 만들어진 소프트웨어이기 때문에 현대의 빠른 빌드를 요구하는 환경에는 적합하지 않을수도 있다. 그래서 여러가지 빌드시스템이 만들어졌고 사용되고 있다.
- Cmake
- Ninja (Chromium, Andriod Soong빌드 등)
- Meson (Systemd 등)
- Cargo (Rust)
거의 대부부분의 UNIX 유틸리티는 빌드할때 아래와 같은 과정을 거치도록 만들어졌다.
./configure로 옵션으로 전달받은 Feature를 추가/제거하고 현재 호스트의 운영체제와 환경등을 고려하여Makefile을 생성한다.make로 실제 소스코드를 빌드하고.make install로 사용자의 환경에 install한다(실행파일과 라이브러리등을 적절한 path에 배치한다). 가령 grep-3.7 의경우 이렇게 빌드한다.$ ./configure $ make $ make installUNIX 유틸리티중 하나를 찾아서 소스코드를 다운로드 받아보자(Grep-3.7 다운로드). 소스코드 압축을 풀면 configure 파일이 존재한다. 이는 Makefile을 생성하는 쉘스크립트이다. 나는 소스코드에서 configure 파일의 라인수를 보고 내 두 눈을 의심했다. 파일이 5만 라인이 넘었기 때문이다. 이걸 인간이 짤 수 있다는 말인가? 유틸리티 소스코드도 작성하기 힘든데 빌드시스템을 위해 이렇게 많은 스크립트를 작성해야 한다는 말인가? 하는 생각들에 아찔해졌다. 하지만 파일 상단 주석에 이렇게 쓰여있었다.
Generated by GNU Autoconf 2.71 for GNU grep 3.7.다행히도 configure 스크립트는 자동생성 되는것이다. 바로 autoconf 라는 프로그램이 자동으로 생성해준다. autoconf가 얼마나 많은 라인을 만들어내는지 간단한 autoconf 스크립트를 작성해 실험해보자.먼저 디렉터리 하나를 생성하고 autoconf.ac 라는 파일을 생성하여 아래의 두 줄을 작성한다. autoconf.ac 이 configure 파일을 생성하기 위해 사용자가 작성해야할 파일이다. 자세한 내용은 아래에서 다시 설명할 것이다.
AC_INIT([helloworld], [0.1]) AC_OUTPUT그리고 Shell에서 autoconf 프로그램을 실행한다. 그러면 아래와 같이 configure 파일이 생성된것을 알 수 있다.
$ aclocal $ autoconf $ ls autom4te.cache configure configure.ac그리고 configure파일을 열어서 확인해 보자. 고작 두줄짜리로 부터 얼마나 많은 라인의 configure스크립트가 자동생성되었는지… (나는 2402라인이 생성되었다.).
TL;DR
이제 autotools 를 이용해 간단한 helloworld 프로그램의 소스코드 패키지 레이아웃을 UNIX스럽고 프로페셔널 해보이게(?) 구성해보자. 결론부터 이야기하면 GNU autotools 에서 사용하는 도구는 다음과같이 두가지다.
- configure.ac 파일로 부터 configure 파일 생성 명령어
$ autoconf - Makefile.am 파일로 부터 Makefile.in 생성 명령어
$ automake --add-missing
-
Publishing my project to Homebrew
1. 개요
UNIX 계열 운영체제는 각각 여러가지 Package Manager가 존재한다. 우분투 같은 Debian 계열의 리눅스 배포판은 APT-based package management 도구를 제공한다. Red Hat계열의 리눅스 배포판에서는 RPM이라는 Package Manager를 제공한다. Package Manager 종류에 대한 자세한 내용은 위키피디아 문서를 참고. MacOS 에서는 Homebrew라는Package Manager를 많이 사용하는데. Homebrew에 내가만든 소프트웨어를 Publish하여 사람들이 쉽게 내 소프트웨어를 다운받고 설치할수 있게 만들어보자. 내가 조사한 바로는 아래와 같이 두 가지 방법이 있다.
-
Homebrew-core 에 등록
brew install <my-project>로 설치가능하게 되는 공식적인 방법. homebrew-core github repo에 Pull Request를 보내면 되는듯 하다. 자세한 내용은 다음의 Documentation를 참고하면 된다. Adding-Software-to-Homebrew -
Brew tap 으로 설치
homebrew 공식 릴리즈에 포함되지 않더라도 등록할 수 있는 방법이다. 결과는 brew tap 으로 repo를 추가할수 있게된다. 참고로 Tap 은 homebrew에서 제공하는 third-party 저장소를 등록하는 방법이다. 등록 이후에 아래와 같은 방법으로 해당 소프트웨어를 설치 할 수 있다. 참고 문서: https://federicoterzi.com/blog/how-to-publish-your-rust-project-on-homebrew/$ brew tap jihuun/rsdic $ brew install rsdic
이 문서에서는 2번 방법에대해 알아볼 것이다. 예제로 사용한 Publish 대상은 내가 만든 터미널용 영어사전인 rsdic이다. 이 프로젝트는 Rust로 작성되었으며 이 문서에는 Rust 관련 내용이 일부 포함될 수 있다.
2. Homebrew에 프로젝트 등록하기
2.1. 내 프로젝트 바이너리 생성 및 release
-
*.tar.gz압축파일 생성
조금 뒤에 살펴볼 homebrewFormula에서 *.tar.gz 로 압축된 바이너리를 필요로한다. 우선 프로젝트를 빌드하여 실행파일을 생성한 뒤에 *.tar.gz로 압축 하면된다. Rust에서는cargo build --release하면 쉽게 릴리즈 바이너리를 빌드할 수 있다.cargo build --release cd target/release tar -zcvf rsdic.tar.gz rsdic -
sha256 해시 생성
생성한 압축파일에 대한 해시값도 추후 homebrewFormula에 추가해야 한다. 빠르게 검색하기 위한 용도인듯 하다.$ shasum -a 256 rsdic.tar.gz f65f3265654fd662fd37334122cd2f97f3b85de12969dae81d0484f30cebeceb rsdic.tar.gz -
바이너리 링크 생성
Github Release에.tar.gz 바이너리 업로드 하고 아래와 같은 링크를 생성한다. https://github.com/jihuun/rsdic/releases/download/v0.1.0/rsdic.tar.gz
2.2.
homebrew-rsdicGithub repo 생성-
homebrew-rsdicGithub repo 생성
Github repository를 하나 생성한다. 저장소 이름은homebrew-<projectname>와 같은 방식으로 해야한다. 자세한 이유는 Homebrew 네이밍 컨벤션 참고. -
Formula작성
Formula는 Ruby 파일인데 딱히 Ruby지식을 필요로 하지는 않는다(나도 모름). 생성한 repository는 아래와 같은 디렉터리 구조를 필요로 한다.- Formula/ - <projectname>.rb - README.md -
Formula/rsdic.rb 생성
Formula/rsdic.rb 파일을 생성하고 아래의 내용을 추가한다.# Documentation: https://docs.brew.sh/Formula-Cookbook # https://rubydoc.brew.sh/Formula # PLEASE REMOVE ALL GENERATED COMMENTS BEFORE SUBMITTING YOUR PULL REQUEST! class Rsdic < Formula desc "A eng-kor dictionary for the terminal users" homepage "https://github.com/jihuun/rsdic" url "https://github.com/jihuun/rsdic/releases/download/v0.1.0/rsdic.tar.gz" sha256 "f65f3265654fd662fd37334122cd2f97f3b85de12969dae81d0484f30cebeceb" version "0.1.0" def install bin.install "rsdic" end end -
commit 생성하고 push
여기까지 하면 Homebrew를 통해 내 프로젝트를 다운로드 받을 수 있다. 실제 커밋 참고. https://github.com/jihuun/homebrew-rsdic/commit/a02f6db3f50a5111ade52e2f31f3c963f97db844
3. 패키지 설치해보기
-
brew tap으로 third party repo등록$ brew tap jihuun/rsdic ==> Tapping jihuun/rsdic Cloning into '/usr/local/Homebrew/Library/Taps/jihuun/homebrew-rsdic'... remote: Enumerating objects: 5, done. remote: Counting objects: 100% (5/5), done. remote: Compressing objects: 100% (4/4), done. remote: Total 5 (delta 0), reused 5 (delta 0), pack-reused 0 Unpacking objects: 100% (5/5), done. Tapped 1 formula (29 files, 24.2KB). -
Package install
$ brew install rsdic ==> Installing rsdic from jihuun/rsdic ==> Downloading https://github.com/jihuun/rsdic/releases/download/v0.1.0/rsdic.tar.gz ==> Downloading from https://github-releases.githubusercontent.com/364442112/3c316f00-adc4-11eb-88cd-b249eab44c28?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Crede ######################################################################## 100.0%
4. 추후 릴리즈 자동화
이제 새 버전 릴리즈시 homebrew-rsdic repo에서 rsdic.rb 파일에 내용을 업데이트 하여 반영하면 된다. Travis 같은 CI/CD 툴로 버전 릴리즈후 brew에 바이너리 업데이트 과정을 자동화 하면 좋을 것 같다.
-