13. Floating point numbers
- VFPv2 Registers:
s0~s31,d0~d15 - Arithmetic operations
- Load and store
- Movements between registers
- Conversions
- fpscr 변경
- 참고:
mrsmsr명령어 - Function call convention and floating-point registers
- Assembler
- 참고
from the IEEE754
sign(부호) | exponent(지수) | mentissa(가수)
(가수)x2^(지수)
single-precision floating point: 단정밀도, 32bit
double-precision floating point: 배정밀도, 64bit
연산속도는 배정도가 1.5~2배 느리다.
VFPv2 Registers: s0 ~ s31, d0 ~ d15
ARM은 부동소수점 연산을 위한 Special register를 가지고 있다. 이름은
single precision : s0 ~ s31
double precision : d0 ~ d15
3종류의 컨트롤 register를 가지고 있다fpscr : cpsr과 유사 N,Z,C,V flags를 가지고 있음
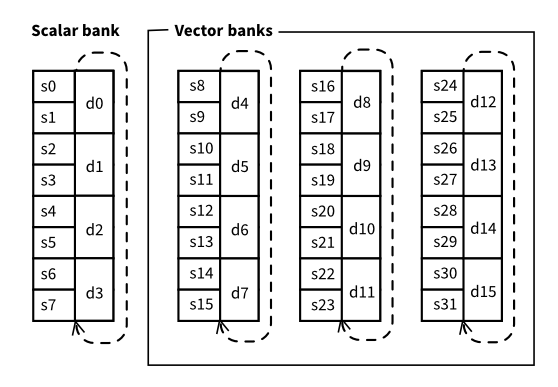
그림: 순서대로 bank 0, 1, 2, 3 인듯
Arithmetic operations
두 종류의 산술연산 형식이 있다.
* `vname Rdest, Rsource1, Rsource2`
name은 명령어로 대체
* `fname Rdest, Rsource1`
그리고 세 종류의 연산 모드가 있다.
* Scalar : bank0 사용
* Vectorial : bank 1/2/3 사용
* Scalar expanded : 혼합해서 사용?
// For this example assume that len = 4, stride = 2
vadd.f32 s1, s2, s3 /* s1 ← s2 + s3. Scalar operation because Rdest = s1 in the bank 0 */
vadd.f32 s1, s8, s15 /* s1 ← s8 + s15. ditto */
vadd.f32 s8, s16, s24 /* s8 ← s16 + s24
s10 ← s18 + s26
s12 ← s20 + s28
s14 ← s22 + s30
or more compactly {s8,s10,s12,s14} ← {s16,s18,s20,s22} + {s24,s26,s28,s30}
Vectorial, since Rdest and Rsource2 are not in bank 0 */
vadd.f32 s10, s16, s24 /* {s10,s12,s14,s8} ← {s16,s18,s20,s22} + {s24,s26,s28,s30}.
Vectorial, but note the wraparound inside the bank after s14. */
vadd.f32 s8, s16, s3 /* {s8,s10,s12,s14} ← {s16,s18,s20,s22} + {s3,s3,s3,s3}
Scalar expanded since Rsource2 is in the bank 0 */
vadd.f32: single-precision 의 add 연산
vaddne.f32이런식으로 predication도 가능 (not eq 일때 add 하라)
Load and store
vldr vstr 을 사용해서 부동소수점 값을 load/store할 수 있다.
vldr s1, [r3] /* s1 ← *r3 */
vldr s2, [r3, #4] /* s2 ← *(r3 + 4) */
vldr s3, [r3, #8] /* s3 ← *(r3 + 8) */
vldr s4, [r3, #12] /* s3 ← *(r3 + 12) */
vstr s10, [r4] /* *r4 ← s10 */
vstr s11, [r4, #4] /* *(r4 + 4) ← s11 */
vstr s12, [r4, #8] /* *(r4 + 8) ← s12 */
vstr s13, [r4, #12] /* *(r4 + 12) ← s13 */
이런 연산이 가능
vldm indexing-mode precision Rbase{!}, floating-point-register-set
vstm indexing-mode precision Rbase{!}, floating-point-register-set
다수레지스터 연산인 ldm/stm도 가능
vldmias r4, {s3-s8} /* s3 ← *r4
s4 ← *(r4 + 4)
s5 ← *(r4 + 8)
s6 ← *(r4 + 12)
s7 ← *(r4 + 16)
s8 ← *(r4 + 20)
*/
vldmias r4!, {s3-s8} /* Like the previous instruction
but at the end r4 ← r4 + 24
*/
vstmdbs r5!, {s12-s13} /* *(r5 - 4 * 2) ← s12
*(r5 - 4 * 1) ← s13
r5 ← r5 - 4*2
*/
Addressing mode, as/bs
vpush {s0-s5} /* Equivalent to vstmdb sp!, {s0-s5} */
vpop {s0-s5} /* Equivalent to vldmia sp!, {s0-s5} */
Stack Operation
Movements between registers
register간 데이터 이동시: mov 명령어.
vmov s2, s3 /* s2 ← s3 */
vmov s2, r3 /* s2 ← r3 */
r#과s#를 혼용해서 사용한 경우 비트만 복사될 뿐, data가 복사되는것이 아님을 주의
Conversions
vcvt.f64.f32 d0, s0 /* Converts s0 single-precision value
to a double-precision value and stores it in d0 */
vcvt.f32.f64 s0, d0 /* Converts d0 double-precision value
to a single-precision value and stores it in s0 */
vmov s0, r0 /* Bit copy from integer register r0 to s0 */
vcvt.f32.s32 s0, s0 /* Converts s0 signed integer value
to a single-precision value and stores it in s0 */
vmov s0, r0 /* Bit copy from integer register r0 to s0 */
vcvt.f32.u32 s0, s0 /* Converts s0 unsigned integer value
to a single-precision value and stores in s0 */
vmov s0, r0 /* Bit copy from integer register r0 to s0 */
vcvt.f64.s32 d0, s0 /* Converts r0 signed integer value
to a double-precision value and stores in d0 */
vmov s0, r0 /* Bit copy from integer register r0 to s0 */
vcvt.f64.u32 d0, s0 /* Converts s0 unsigned integer value
to a double-precision value and stores in d0 */
fpscr 변경
/* Set the len field of fpscr to be 8 (bits: 111) */
mov r5, #7 /* r5 ← 7. 7 is 111 in binary */
mov r5, r5, LSL #16 /* r5 ← r5 << 16 */
vmrs r4, fpscr /* r4 ← fpscr */
orr r4, r4, r5 /* r4 ← r4 | r5. Bitwise OR */
vmsr fpscr, r4 /* fpscr ← r4 */
vmrs: fpscr을 general purpose register에 load하는것 대신에 mrs 명령어 사용가능vmsr: register 에서 다시 fpscr에 전달
참고: mrs msr 명령어
cpsr 또는 spsr control하는 명령어 (PSR 명령)
CPSR과 SPSR 두개와 일반 Register 사이를에 값을 서로 복사할 수 있는 명령어들을 말한다. MRS, MSR 두개로 모든걸 처리한다.
mrs r0, cpsr
r0에cpsr값을 읽어온다.
msr cpsr, r0
r0의 내용을cpsr에 복사 한다.
Function call convention and floating-point registers
http://thinkingeek.com/2013/05/12/arm-assembler-raspberry-pi-chapter-13/ 읽기
Assembler
Make sure you pass the flag -mfpu=vfpv2 to as, otherwise it will not recognize the VFPv2 instructions.